●变汉字英雄为人人汉字问不倒●
近年、河南卫视的《汉字英雄》及中央电视台的《中国汉字听写大会》,有力的推动了人们去争取复兴中华文化和汉字文化中国梦的实现。还有更深入的活动值得开展,如根本消除汉字难查落后于西文的国耻,让中小学生都成为汉字问不倒的能人。
赛出的汉字英雄们都有用字词典强化训练的历程,他们用的字典与查法都是远远落后于西文字典查法。而现在早已有了一批像西文查法一样便用的汉字查法,尽快普及它们,别再让小学生们汉字难查懒于查字浪费时光。
上世纪八十年代CCTV蛇年春节晚会上,有个背字在《新华字典》中页码的惊人节目。这世纪CCTV的一次《小崔说事》节目中,一位号称字典问不倒的工人表演,观众随便提问一个字,那工人就可说出在《新华字典》中的页码。这两次节目证明中文字典难查,一个人若能知道一个字在字典中的页码,就是可以上电视表演的奇事,这岂不是显示汉字难查落后这国耻吗。
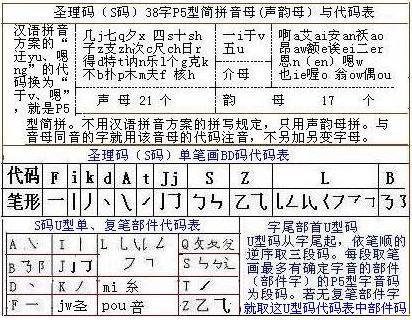
小学查字教的汉语拼音方案、规范部首、高考前夕为应试补教的四角号码,都远不如西文字典法好。若用教这些的一小半时间,改教S码注音识字查字打字法,就可根本解决识字查字打字难题及缓解提笔忘字症。网上圣理书院早已推出了圣理码(S码)法,S码注音识字查字打字的教参、字典、打字码早已可在网上免费下载到。这里只作些简介。
S码注音识字查字打字入门五步法中,第一、二步安排在小学一册的前两个月,教简化的拼音的S码简拼注音识字查字打字。第三月配合逐笔学写字开始S码法第三步教单笔画BD码查字打字。

单笔画BD码代码助记口诀为:
横F 竖i k撇笔 ,点d 捺A 提笔t。 ZSJL形相似,7形L 3形B。
笔形与代码间有许多音形联想便记因素而不难很快记住,如点与提(挑)笔是分别用声母d.t作代码,BJLSZ都与它们代表的笔形有形似关系,如乙字形折笔代码是字母Z。
用一二十分钟让小学生熟习一下各笔形代码与PD或DP码。
拼音后加首次尾笔BD码,就是PD型音形码。
首次尾笔BD码后加拼音,就是DP型形音码。
当堂就可用一二十分钟口试比赛或开卷笔试,看着代码表要求说出或写出课本中已学会写的字的PD码或DP码。课尾用几分钟小结与补充,如说:在国标一二级字(国标GB2312字表中的近七千字)中,PD码或DP码都没有超过十个同码字的组,字的PD码或DP码就是字在国标字典中的页码。因此BD、PB码把拼音与旧部首查字各个难点一扫而光,汉字可以像西文一样好查字。
第二课补充BD型纯形码,取前四笔BD码后再取末笔码(四头一尾码),倒数第二笔码……
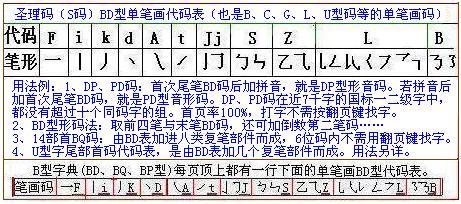
当堂也可用一二十分钟口试比赛或开卷笔试,看着代码表要求说出或写出课本中已学会写的字的四头一尾码。可把编课本生字的PD码、BD码检字表作课后练习巩固BD码法。这样,一般小学生都可能成为字典问不倒的汉字英雄。
网上可免费下载到的《笔顺字音八部首BD型字典》,可配合这教学用。
S码法第四步安排是,小学一册的第四月教单笔画BD码加进八类复笔部件的14部首BQ码。
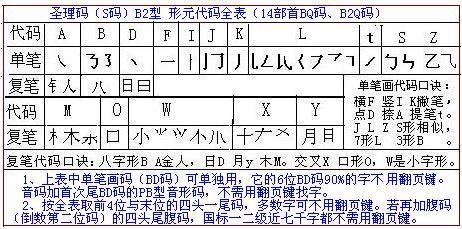
S码法第五步安排是,小学语文第二册教S码C、U型码查字打字。这里只简介U型码。
汉字是由笔画等于或少于整字的单、复笔部件构成。部件的结构种类,不外乎是字或非字的单、复笔部件这两种可能情况。在S码中,是字的部件简称部件字。没有一个通用字音的单、复笔结构,简称非字部件。
如“一、乙”字是由等于只有一笔的单笔画部件构成,各是一个部件字。“二”字是由两个横笔部件组成,也可说是由两个部件字“一”叠成。“川”字由三个非字的单笔画部件构成。“利”是部件字“禾”与非字部件“刂”构成,“旧”是非字部件的竖笔与部件字“日”构成。
汉字是以形声、会意字及有形旁、音旁等为主的体系。非字部件或形旁,多出现在字首,即左边或上面。部件字或音旁(声旁)多在字尾,即右边或下面。S码U型根据字尾部件多是便于知道字音的部件字这特点,约定把字尾的部件作为部首来归类汉字,所以叫字尾部首法。
U型码的代码表,是由单笔画BD型代码表补充进几个复笔部件而成,复笔部件代码如“攵q”。因此只要熟习了前面的拼音与BD码,就很容易进而掌握U型码查字打字。
U型码取码编码查字打字用法要点:
①、U型码约定按规范笔顺的逆序分段取部件码查字打字。
②、五段分段法为:字尾段(尾段、末段、倒一段),与尾段相邻的倒二段,与倒二段相邻的倒三段,整字的P5型简拼音码段,整字的汉语拼音方案注音段。取段码时尽可能取笔画多的部件,同码字就少些。
③、部首码与各段的取码编码约定是,字尾部件若是字,就用这部件字的P5型简拼码作字尾部首段的代码。字尾部件若不是字,必是U型码代码表中非字的单、复笔部件,就用该部件码作该段的段码。
如“古”上面是部件字“十”,下边是部件字“口”,字尾部首码是部件字码“口kou”。“故”左边是部件字“古”,右边是非规范通用字的复笔部件“攵”。“故”的字尾部首码是非字的复笔部件码“攵q”。
④、与字尾部首段代码相同的字,再取相邻段的段码查。段码的取码法与字尾部首段的取码法一样,相邻段的部件若是字,就用这字的P5型简拼码作段码。相邻段若不是字,就用相邻的U型部件代码作段码。
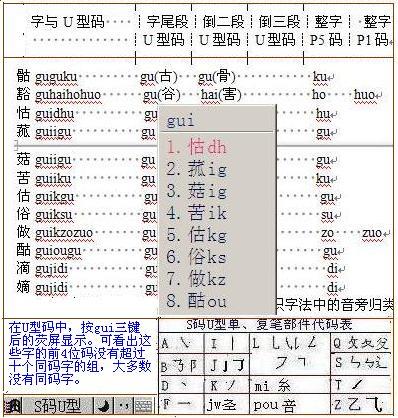
如“做”的字尾部首码是部件字码“故gu”,而不取笔画少的部件码“攵q”。相邻的倒二段、倒三段码分别是竖笔i,撇笔k,“做”的U型码是guik(故gu、亻ik)。
这样取码编码,近七千字的国标一二级字中,只需取倒三段的前6位字母码,就没有超过十个同码字的组了。
字的U型码如:口fli、十if、古koush、故qgu、做guik。小学一年级生可能很快就用熟这查字法,不难一见字就能说出字在字典中的页码(前五六位U型码),表演字典问不倒。
这U型字尾部首字典,最便配合集中识字法中的音旁归类的字族识字法用,所以又叫音旁字族字典。如下表中就是“古”字族中的一段。U型码便作有趣的字族追踪字滚字速成识字游戏,帮助小学生早日成为汉字英雄。U型码查字打字性能比汉语拼音方案法好,常用它可较好抗击当前提笔忘字的流行病。
U型码字典中“做”前后相邻字的U型码与注解
┌┈┈┈┈┈┈┈┬┈┈┈┬┈┈┈┬┈┈┈┬┈┈┈┈┈┈
┊字与U型码 ┊字尾段┊倒二段┊倒三段┊整字┊ 整字
┊ ┊U型码┊U型码┊U型码 ┊P5码┊P1码
└┈┈┈┈┈┈┈┼┈┈┈┼┈┈┈┼┈┈┈┼┈┈┈┈┈┈
骷guguku gu(古) gu(骨) ku
豁guhaihohuo gu(谷) hai(害) ho huo
怙guidhu gu i d hu
菰guiigu gu i i gu
菇guiigu gu i i gu
苦guiiku gu i i ku
估guikgu gu i i gu
俗guiksu gu i k su
做guikzozuo gu i k zo zuo
酤guiougu gu iou gu
滴gujidi gu j i di
嫡gujidi gu j i di