近期由于“茅盾文学奖” 和科学院院士增选等事项,公平选举一词在互联网上颇为惹眼。本文从技术层面,应用信息论的熵概念,提出选票统计的信息熵方法,以增加评选过程的科学性和透明度。此方法可以进一步推广到地区、企业和组织机构的业绩评估等方面,用信息分布修正系数,给出总业绩的综合指标。
1. 问题提出
假设投票人共20位,分别来自4个部类 (部门、分区或专业):I, II, III, IV,每个部类有6位投票人,满票为24张。候选人共有5位:A, B, C, D, E,共需选出3人。表一给出投票结果。
表一 6个部类投票人对5位候选人的投票结果。
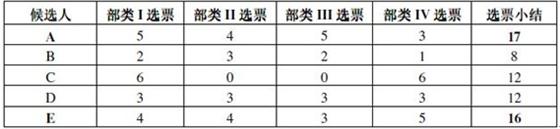
由此投票结果看出,候选人A以17票和候选人E以16票当选;候选人C和D同获12张票,一时难于确定他们两位谁应当选。现实生活中,往往因为时间和资源等原因,不可能进行多轮选举。需要用科学方法,在候选人C和D间选取一位。分析表一,可以发现,候选人C的选票都集中在部类I和部类IV,而候选人D的选票来自各部类。这种信息分布不确定现象,可以用信息理论的熵概念给出量度,进而区分两位候选人选票的有效性。
2.信息熵概念
信息论的创始人申农(Claude Shannon)1949年引入了一个重要概念:信息传播的不确定性。信息论指出,如果一个事件有n个等可能性的结局,那么结局未出现前的不确定程度h与n的对数成正比。
有一枚硬币,可把头像的那面称为正面,另一面称为反面。如果投币看其结果是正面还是反面,这是一个不确定问题:正反面朝上的概率各为一半。假设样本空间(Sample space) X 有 n 的基本事件 (events),其基本事件 xi 的概率为 pj, j=1, 2, …, n, ∑ pj = 1。申农的信息理论,给出度量这一不确定性的信息熵函数:
h (p1, p2, …, pn) = ∑ - pj Log (pj), j = 1, …, n, (1)
式中,Log 为以2为底的对数。
图一表示投硬币不确定性的信息熵分布曲线。在正反面朝上的概率各为一半时,不确定性最大,信息熵为1。若有人作弊,把正面出现的概率固定为1,反面出现的概率固定为0,此时投硬币不确定性最小,信息熵为0。 同样,正面出现的概率固定为0,反面出现的概率固定为1,此时投硬币不确定性亦为最小,信息熵为0。
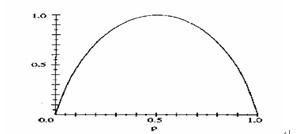
图一 投硬币的不确定性:信息熵分布曲线
在申农的信息理论具体应用方面,笔者1988年使用信息熵来表达复杂系统结构有序度,并提出相应算法;2011使用信息熵定义网熵指数(W-entropy Index)模型和系统来评价社交网络成员影响力。
3.选票统计信息熵模型
假设此次选举某候选人用Pi表示,i = 1, …, m,共有m个候选人。某部类共有Tj投票人,j = 1, …, n,共有n个部类;有效票总数为 V = ∑ Tj。某候选人Pi在部类j,获得的选票为Vij,在该部类的获票比为:pij = Vij/ V,i = 1, …, m,j = 1, …, n。表达各部类重要程度的权重集合为:{ a1, a2, …, an },∑ aj = 1。由此,候选人Pi获票平均统计值为:
Vm = ∑ aj Vij,j = 1, …, n, (2)
如果对选票的分布理解为信息传递的分布现象,可以用信息熵来衡量选票的有效性,信息熵定义为评价候选人的信息量在各部类获票数的修正系数,对(2)式进行修正。
在使用信息熵计算公式(1)之前,应先定义pin+1 = 1- ∑ pij表示候选人在各部类没获票比,则有选票不均匀分布修正系数应为:
h (pi1, pi 2, …, pin, pin+1) = ∑ - pij Logn+1 (pij), j = 1, …, n+1, (3)
式中,Logn+1 为以n+1为底的对数。h值介于[0,1]之间。
由(2)和(3)式,对候选人获得的选票为Vij修正,则有效选票为:
VTij = h *Vij (4)
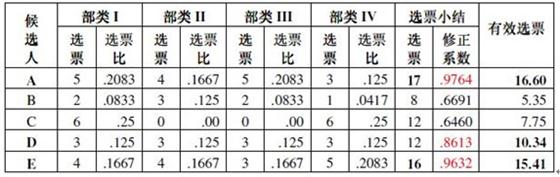
由(3)式对表一6个部类投票人对5位候选人的投票结果修正,得表二结果。候选人A获17票,选票分布修正系数为0.9764,有效选票为16.60;候选人E 获16票,选票分布修正系数为0.9632,有效选票为15.41;候选人D 获12票,选票分布修正系数为0.8613,有效选票为10.34;候选人C 获12票,选票分布修正系数为0.6460,有效选票为7.75;所以候选人A 、B和D以有效选票数前三名当选。
尽管候选人C 和D同获12张票,但由于C的选票分布不均匀,没有代表性,所以落选。此结果应该是与实际情况相符合的。
表二 6个部类投票人对5位候选人的投票结果修正
4.结语
以上分析结果表明,信息理论的熵概念可以应用到选票统计过程中,给出在难以确定有效选票情况下的解决方案。此算法可以进一步推广到地区、企业和组织机构的业绩评估等方面,用信息分布修正系数,给出总业绩的综合指标。
参考资料
[1] Shannon, C., 1949, Communication Theory of Secrecy Systems. Bell System Technical Journal, 28 (4): 656-715.
[2] 李伟钢,复杂系统结构有序度--负熵算法[J]. 系统工程理论与实践,1988, 8(4): 15-22。
[3] 李伟钢,社交网络成员影响力分析-W熵,千人计划超搏,2011。
http://www.1000plan.org/superblog/2597/256
[4] Li Weigang, Zheng Jianya and Daniel Li, W-entropy Index: the Impact of Members on Social Networks, WISM 2011, Taiyuan, China. Gong et al. (Eds.): WISM 2011, Part I, LNCS 6987, pp. 226-233, Springer-Verlag Berlin Heidelberg.